
Don’t touch my crime scene
Why people who work with data and algorithms sometimes appear to hate it when you help them with data and algorithms.

A couple weeks ago, the Prefect team put out a tidy little demo of their ChatGPT+ data bot: Marvin AI. It looks harmless—a data cleaning script that imputes missing values.
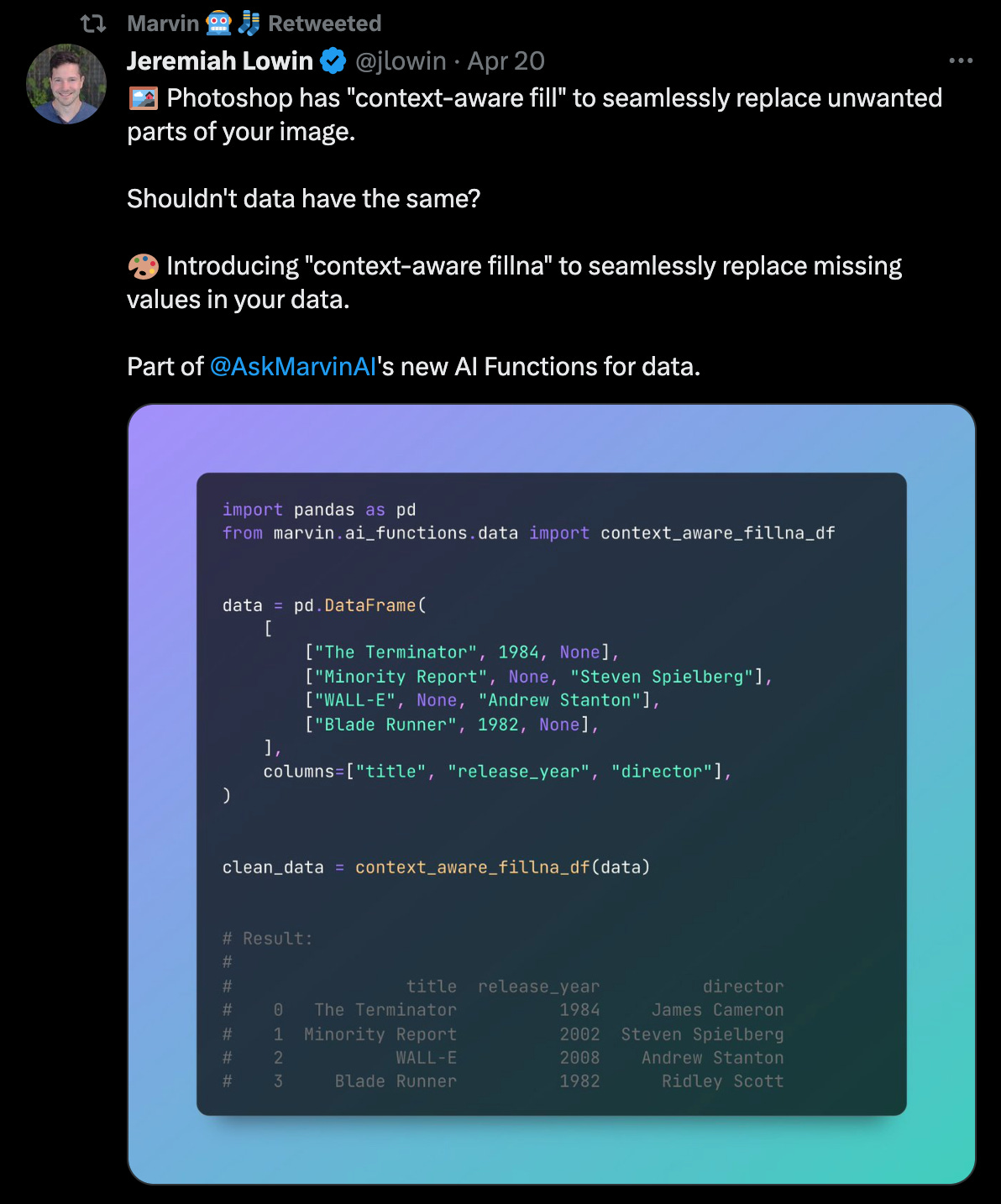
Data twitter Did Not Like it.

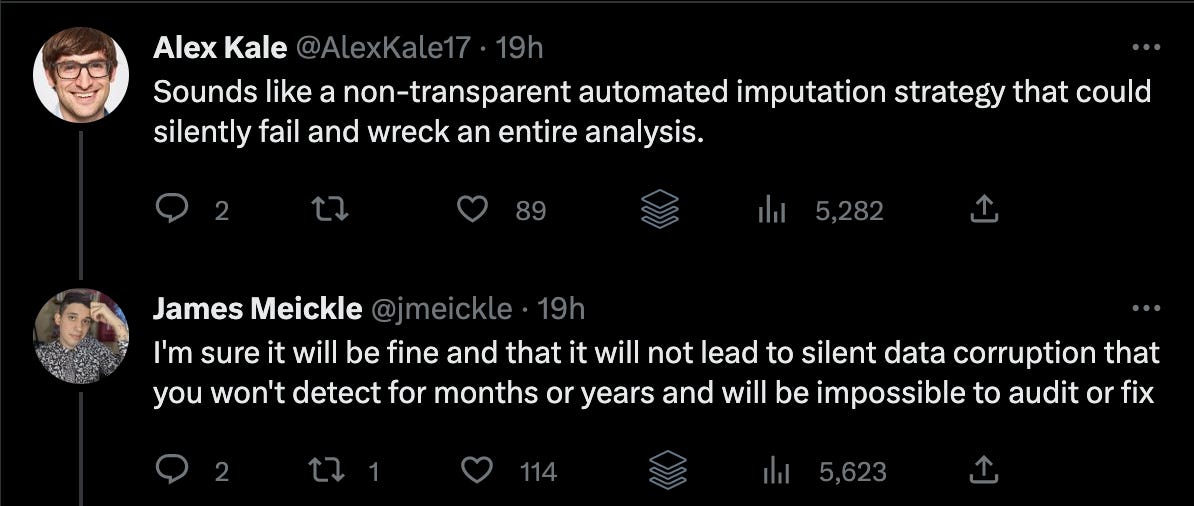
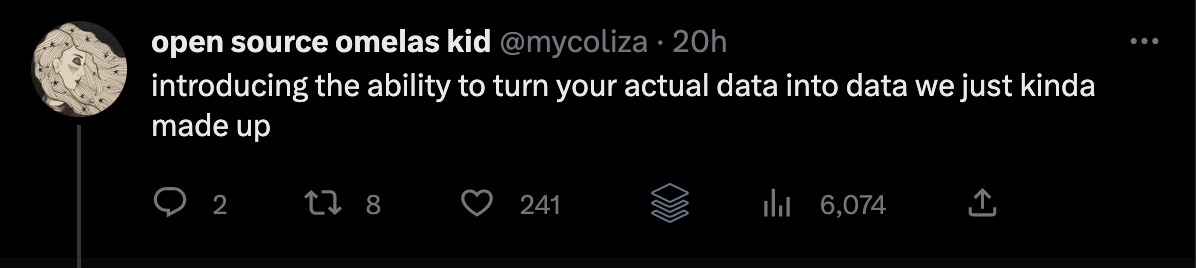

Rarely have I seen so much hate and fury directed at what looks like such a cute and innocent example.
Why are data people so infuriated by this bot? We spend so much time complaining about messy data, data cleaning, and data prep. You’d think we’d appreciate a little help!
This isn’t an isolated example. Personally, I’ve had lots of frustrating encounters with upstream software teams and data vendors, where their attempts to help me with my analysis just got in the way. You can also find other cases of data people raging at attempts at helpful improvements in civic data sharing, academic transparency and replicability, and data ethics.
This post is about mutual understanding: why people who work with data and algorithms sometimes appear opposed to data and algorithms.
If you’re a data-adjacent person, wishing to understand the strange and intricate folkways of data analysts, data scientists, analytics engineers, etc., I can help you untangle this conundrum.
Conversely, if you’re a data person and wish to explain to your colleagues why helpful manipulation of your data is usually a Very Bad Idea, this article is for you.
Let’s start with a metaphor, then get more technical.
Data sleuthing: Holmes vs Lestrade
Data and algorithms people sometimes hate on data and algorithms for the same reason that Sherlock Holmes, a detective, sometimes hates on Inspector Lestrade, also a detective.
 - Baker Street Wiki - The Sherlock Holmes encyclopaedia")
There's a touch of professional disdain, sure. “That Lestrade guy is an overeager bumbler who just doesn't get it.” But the root cause for the disdain is that Lestrade sometimes screws up Sherlock's cases.
Lestrade arrives on the crime scene first. He pokes around, without knowing quite what to look for. In the process, he tramples footprints, moves furniture, smudges fingerprints, and so on. Lestrade’s misguided attempts at detectiving often erase clues that make it harder for Sherlock to do his job once he arrives on the scene.
The job of a Sherlock-Holmes-style detective is to work backwards from clues (data) to make logical inferences about What Happened And Why. This is also the core of most data work: “Was the launch campaign successful? Which feature had a bigger impact? Are users reacting more strongly to version A or B?”
The difference is that detectives have to work with what they’re given. They show up after a crime has been committed and have to glean whatever they can from the scene.
In contrast, professional data teams have a lot more control—at least in theory. They actively work to create systems to capture, record, and report on useful data. They can add instrumentation, deploy sensors, and (often) engage directly with product and operations teams to collect the data the business needs to answer crucial questions.
In practice, it's never perfect. The right measures weren’t in place when the experiment started. Logs are missing crucial fields, or their formats change over time. Sensors fail. Servers drop records. Raw data is too big or sensitive to retain forever, so you get records that have been de-identified, downsampled, or rolled up into aggregate statistics.

Data in real life is usually a long, long way away from being perfect. But that doesn’t affect which questions are valuable to answer. As a result, data people inevitably end up spending a lot of their time sleuthing. You get out your magnifying glass, inspect the raw data, and reason backwards about what must have happened in the real world to create those specific patterns. You track down and cross-examine domain experts, even though it’s rare for their version of what happened to be detailed and accurate enough to answer all your your questions.
Data in real life is usually a long, long way away from being perfect, which is why it’s infuriating when some overeager bumbler like Lestrade messes it up even worse by injecting themself into the process.
PS: I started a substack! No idea how often I’ll post or on what topics, other than my normal general interests: craftsman approaches to data, community building, and writing/thinking.
PPS: I know the team at Prefect. They generally understand data workflows, so I’m partly wondering if this was deliberate trolling. If so: job well done.
very interesting information, thanks for sharing with us this topic.
<a href=https://www.achieversit.com/best-software-training-institute-in-hyderabad-for-career-growth-with-100-success-rate---achieversit>
best software institute in hyderabad
software training institutes in kphb
top 10 software coaching centers in hyderabad
best software institute in Hyderabad
</a>